Amazon Proxies for 2026: A Practical Guide for Sellers, Scrapers, and Analysts
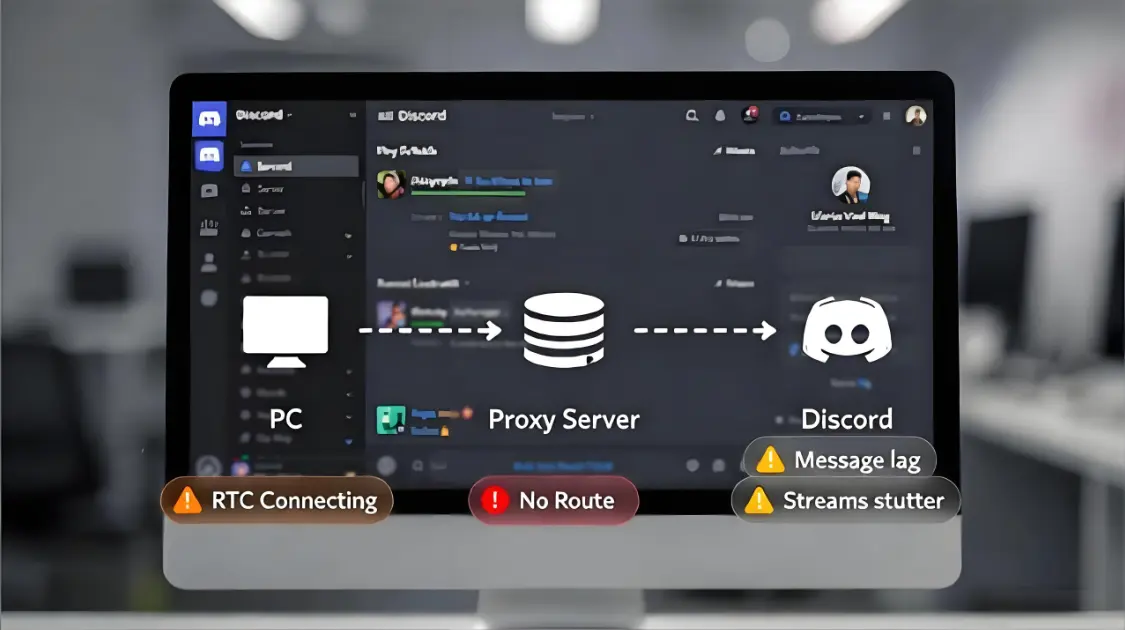
In 2026, people use Amazon proxies for three practical outcomes: keeping seller workflows stable, collecting Amazon data with fewer interruptions, and making market numbers comparable across regions. The same setup rarely works for all three.
This guide breaks the problem into clear paths—seller ops, scraping, and analysis—then explains what usually causes verification loops, rate limits, and CAPTCHAs, what “stable” looks like in each workflow, and the simplest setup changes that improve reliability without making your workflow complicated. If you’re still uncertain about which connection methods matter most, start by understanding the difference between HTTP, HTTPS, and SOCKS in real operations via proxy protocols.
If you’re unsure which connection details matter in real operations, start with Where proxy IPs actually matter before choosing proxy types.
Amazon proxies are used in three practical contexts
Amazon proxies are typically used in three practical contexts, each with very different stability requirements.
Seller operations (multi-store, team access)
The priority is login stability: fewer verification loops, clean separation between accounts, and predictable session behavior.
Scraping and monitoring (catalog, search, SERP)
The priority is survivability at scale: controlled rotation, manageable rate limits, and retry behavior that doesn’t exhaust proxy pools.
Analysis and research (pricing, market data, dashboards)
The priority is data consistency: precise geo control and repeatable sampling, otherwise the dataset becomes misleading.

Because these contexts behave differently, proxy requirements diverge quickly:
- Seller Central and account work tend to rely on sticky sessions, stable geography, and low IP reuse to maintain identity continuity.
- Price monitoring and collection depend on measured rotation, pool segmentation, and backoff strategies when limits appear.
- Research and analytics require geo pinning and data hygiene controls to reduce shipping, region, and stock-related bias.
What Amazon tends to flag in 2026
Amazon does not “ban because you used a proxy”. It reacts to signals. Proxies change some signals, but not all.
Common signal buckets that affect proxy choice:
- Geo inconsistency: logins or requests jumping countries/cities too often.
- Network fingerprints: heavy datacenter patterns, odd ISP mixes, noisy subnets.
- IP reuse and reputation: too many unrelated users sharing the same exits.
- Burst behavior: high request spikes, repetitive navigation, tight intervals.
- Session mismatch: cookies, headers, device identity, and route not staying aligned.
Two practical boundaries (important for buying decisions):
- Proxies help when you need a stable region route, separate identities, or distribute load.
- Proxies don’t fix sloppy automation, broken session handling, or inconsistent device/browser fingerprints.
If you need consistent exits at the network layer, set it up once and keep routes stable: Configuring a WireGuard Client on OpenWrt
Anonymized example (seller ops): A 6-store operator reduced repeated 2FA prompts after enforcing “one store → one profile → one pinned route” and removing rapid account switching. Their “unusual activity” banners dropped from “multiple per week” to “rare” within ~10 days (exact rates vary by catalog, operator behavior, and region).
Anonymized example (scraping/monitoring): A small monitoring setup cut 429 spikes by separating “heavy SERP pagination” from “light product detail pulls” and applying backoff before rotation. CAPTCHA events didn’t vanish, but became “contained” rather than spreading across the whole pool.
How to choose proxy types for Amazon proxies
Use this as a purchase filter. Don’t start with brand names. Start with proxy type.
Static residential or ISP proxies
Best when you need predictable identity.
Use them for:
- Seller Central logins and daily operations
- Long-lived sessions (hours to days)
- Account separation (one account, one route)
What “good” looks like:
- Sticky sessions that don’t randomly hop exits
- Stable geo (country—and often city/region if your workflow is location-sensitive)
- Low reuse exits (fewer strangers on the same IP)
A practical buying shortcut: if you’re evaluating identity stability first, you’re effectively evaluating static residential proxies as the default baseline for seller workflows.
Rotating residential proxies
Best when you need coverage and survivability under collection pressure.
Use them for:
- Price monitoring at scale
- Category/search pagination
- Large sampling across products or regions
What “good” looks like:
- Rotation you can control (not “chaos rotation”)
- Pool segmentation by task (separate routes for heavy vs light pages)
- Clear behavior under load (timeouts and retries won’t spiral)
When you’re validating collection survivability, it usually comes down to whether your rotating residential proxies give you controllable rotation and task-level pool separation rather than a single mixed “everything pool”.
Datacenter proxies (when they’re “good enough”)
Datacenter proxies can be fast and cost-effective, but they fail faster in some Amazon paths.
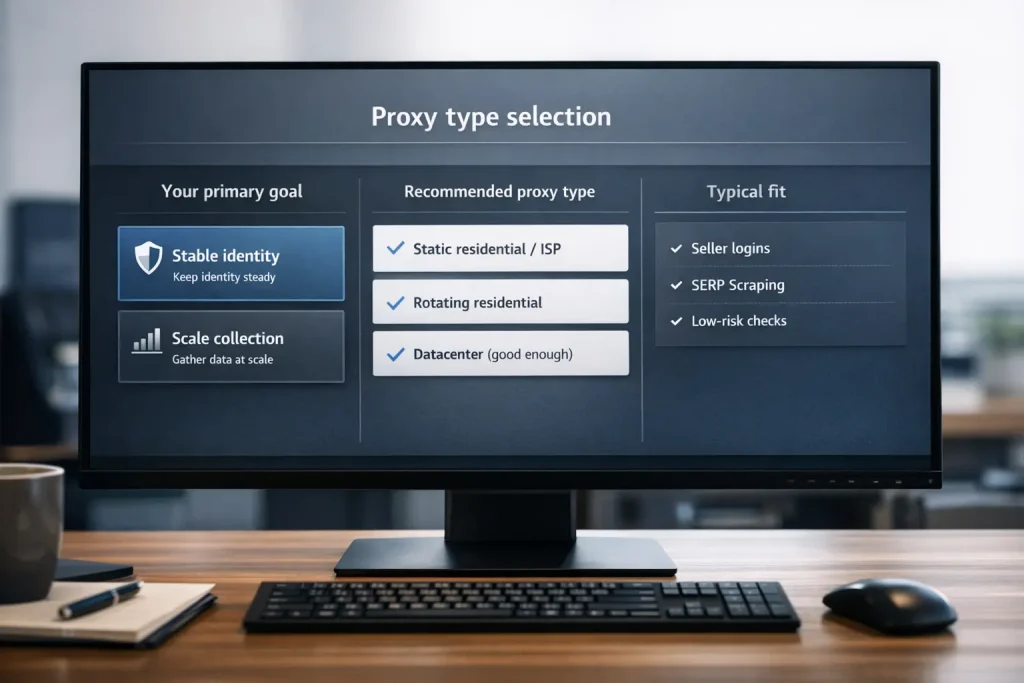
Usually “good enough” for:
- Low-risk, low-volume checks
- Non-login browsing where occasional blocks are acceptable
- Internal tooling that can tolerate resets
Often a poor fit for:
- Sensitive login workflows
- High-scrutiny endpoints that quickly learn subnets
- Teams trying to keep one identity stable for days
A simple rule: if you need identity stability, avoid relying on pure datacenter routes as your primary plan.
Two Amazon proxy setups: stability-first vs. scale-first
Template A: Seller ops (multi-store, stable logins)
Goal: fewer verification loops, less “account linkage noise”, and predictable routes.
1) One account → one environment
- One store account maps to one dedicated browser profile.
- Do not share the same profile across multiple stores.
- Keep cookies and storage isolated.
2) One environment → one stable route
- Pin a static residential or ISP route per store.
- Keep the same region consistently (don’t hop countries “for safety”).
- Keep time-of-day behavior normal for that region.
3) Basic operating hygiene
- Avoid rapid switching between accounts in the same hour.
- Keep session durations natural (don’t log in/out every few minutes).
- If a store needs team access, use role-based access rather than shared credentials.
4) Success signals to track
- Fewer repeated 2FA prompts during normal work.
- Fewer “unusual activity” warnings across the store group.
- Store actions (bulk edits, uploads, listing work) stop triggering re-auth.
If you can’t get these signals after a week, it’s usually one of three issues:
- exits are too reused/noisy,
- geo is drifting,
- profiles are not truly isolated.
A neutral note on providers: some teams prefer vendors that let them pin routes and control session stickiness predictably; a provider like MaskProxy is one example teams mention when they want pricing that stays reasonable while still keeping route control and basic observability.

Template B: Scrapers & analysts (stable collection, cleaner data)
Goal: reduce blocks without destroying your dataset quality.
1) Split tasks into lanes
- Lane 1: light pages (product detail fetches, small volume)
- Lane 2: heavy pages (search results, category pagination, high volume)
Different lanes should not share the same pool.
2) Choose a rotation model
- Time-based rotation: rotate every N minutes for sustained crawling.
- Volume-based rotation: rotate after N requests per exit.
- Error-based rotation: rotate when error thresholds hit.
Pick one primary model. Mixing three at once creates noise and makes debugging impossible.
3) Layered handling for common failures
- 429 / rate limited: backoff first; rotate only if 429s keep repeating.
IfRetry-Afteris present, wait that long before retrying. 429 Too Many Requests and Retry-After - 503 / temporary: retry with jitter; don’t rotate the whole pool on the first hit.
Use exponential backoff with jitter to avoid retry storms. Retry behavior (exponential backoff with jitter) - CAPTCHA / robot checks: treat it as a spike; drop concurrency, rotate a pool segment, and slow the pattern.
If your crawler is headless and sessions drift under retries, this pattern breakdown helps: Headless browser routing for steady sessions
4) Data hygiene (this is where analysts win)
Amazon data changes based on:
- delivery location,
- Prime eligibility,
- stock/fulfillment,
- region-specific pricing.
To keep datasets comparable:
- fix a shipping region per measurement run,
- record the location context with the price,
- sample consistently (same local time window, same region, same route style).
Log the site, delivery ZIP (or region), and Prime status for every record; otherwise you’ll compare different delivery conditions and draw the wrong conclusion.
How to evaluate proxy providers
A provider list is easy. A selection method is what earns trust.
Use a scorecard like this:
| Category | What you’re really testing | What “good” looks like |
|---|---|---|
| IP reuse & reputation | Are exits crowded? CAPTCHAs at low volume? | Low-volume work stays quiet |
| Geo precision | Can you remain region-bound for days? | Low drift, repeatable routing |
| Sticky session reliability | Does “sticky” stay sticky under load? | Session stays stable across normal ops |
| Failure rate under concurrency | What happens at higher threads/operators? | Errors rise gradually, not explosively |
| Latency consistency | Is latency steady, not just fast once? | Predictable p95 behavior |
| Observability | Do you get session controls & useful exit info? | You can debug without guessing |
| Support & policy clarity | Replacement behavior, noisy exit handling | Clear process, not vague promises |
Language that keeps your page credible:
- say “reduce abnormal signals” and “improve stability”,
- avoid claiming “avoid bans” as a guarantee.
The shortest path to a working setup
If you are a seller: build Template A as a minimal loop first. One store. One profile. One stable route. Run it for a week and track verification frequency.
If you collect data: validate Template B on a small sample first. A few ASINs. A few fixed locations. Track 429/CAPTCHA rate and latency. Scale only when the error curve stays stable.
When your route needs both scale and predictability (especially for mixed monitoring + analysis teams), it’s often easier to standardize on a larger pool model and then enforce strict lane separation—some teams do this with unlimited residential proxies so “capacity decisions” stop forcing risky pool sharing.
When amazon proxies match the task—and your setup stays consistent—everything gets quieter: fewer interruptions for sellers, fewer wasted requests for scrapers, and cleaner datasets for analysts.
Daniel Harris is a Content Manager and Full-Stack SEO Specialist with 7+ years of hands-on experience across content strategy and technical SEO. He writes about proxy usage in everyday workflows, including SEO checks, ad previews, pricing scans, and multi-account work. He’s drawn to systems that stay consistent over time and writing that stays calm, concrete, and readable. Outside work, Daniel is usually exploring new tools, outlining future pieces, or getting lost in a long book.
FAQs
Do proxies get detected on Amazon?
Amazon flags patterns + IP reputation. Proxies can help, but noisy exits and geo drift can make things worse.
VPN vs proxy: which works better?
VPN is fine for one identity. For multi-accounts or scale, proxies win because you can control pools + sessions.
Are free Amazon proxies worth it?
Usually no—high reuse and bad reputation mean more verification/CAPTCHAs and wasted time.
Static or rotating: what should I use?
Static (residential/ISP) for logins and long sessions; controlled rotating residential for monitoring/collection. Use datacenter only if resets are acceptable.
How many IPs do we need to start?
Seller ops: start small, keep one store → one route. Collection: size for concurrency, then expand by error rates (429/CAPTCHA).
Why am I still getting CAPTCHAs?
Common causes: overused exits, chaotic rotation, high concurrency, or messy sessions. Slow down, clean sessions, then scale.