Data Aggregation Proxy Routing for Scraping and Monitoring
Most data aggregation pipelines don’t fail because “the proxies are bad.” They fail because routing decisions are unclear: the same pool is used for different targets, rotation is applied at the wrong time, retries turn into storms, and sessions leak across jobs. When scraping, monitoring, and crawling run on schedules, small routing mistakes compound into bans, missing coverage, and unstable results.
This post gives a routing-first, operational way to design proxy layers for data aggregation work. If you want the bigger picture of where proxy IPs matter across modern workflows, start here: Where Proxy IPs Actually Matter in Modern Workflows
What data aggregation needs from routing
Data aggregation routing is about three outcomes:
- Access continuity: keep requests flowing with predictable error rates. You don’t need “unlimited IPs.” You need stable throughput at a known success rate.
- Signal consistency: your pipeline should see consistent pages, prices, and SERP layouts. Routing that changes identity too often can change what you observe.
- Controlled change: when you rotate, it should be deliberate and measurable, not random churn.
Treat routing as part of the collector design, not an infrastructure afterthought. Track collector health in two layers:
- Collection metrics: coverage, freshness, and completeness per target.
- Routing health metrics: block rate, challenge rate, session loss rate, and retry amplification.
If you can’t explain why a request used a given IP pool, rotation rule, and session policy, you don’t have a routing plan yet.
The routing layering model
Use a simple layering model so decisions don’t bleed into each other:
- Target risk
How hard the destination pushes back, and what defenses it uses. - Identity requirements
Whether the job must behave like a stable identity or an anonymous fetcher. - Session strategy
How cookies and tokens are created, isolated, reused, and retired. - IP type and pool
Datacenter Proxies, Residential Proxies, ISP, mobile, and how pools are segmented. - Rotation policy
Fixed, timed, or event-driven rotation with explicit limits. If you’re implementing active rotation at scale, treat it as a dedicated policy surface, not a side effect of retries. See Rotating Proxies for the concept boundary. - Retry policy
What errors get retried, how many times, and with what backoff. - Observability
Logs, tagging, and dashboards that connect outcomes to routing choices.
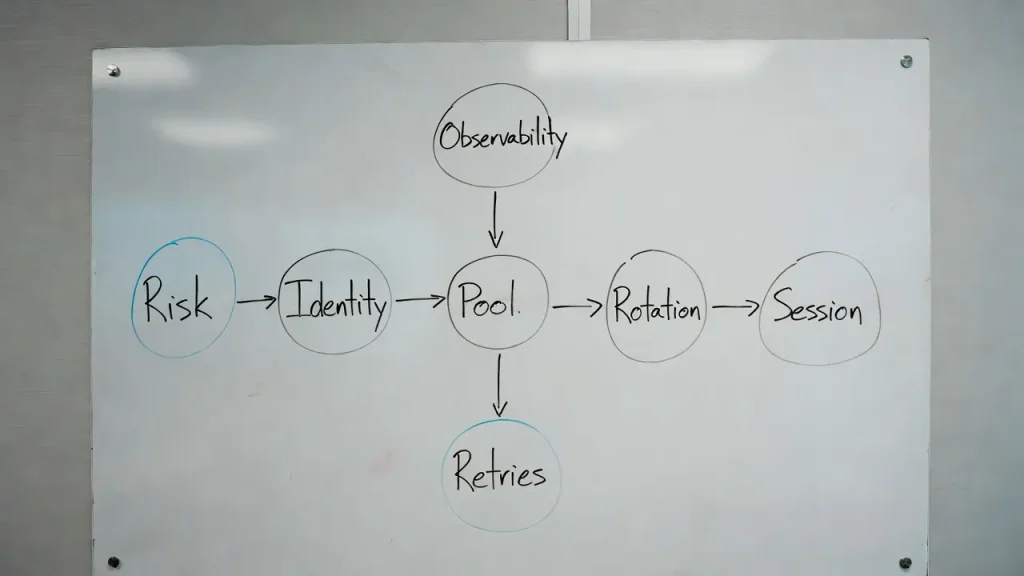
The rule is simple: one layer should not secretly override another. For example, a retry system should not change IP type. That belongs in routing policy, not in a generic HTTP client.
Target risk map and why it changes routing
Start with a risk map. Keep it practical. You’re not trying to predict every defense, only to pick the right routing posture.
Low friction targets
- Public pages with light rate limits
- Few dynamic checks
- Minimal geo sensitivity
Moderate friction targets
- Clear 429 behavior
- Basic bot checks and occasional JS challenges
- Content changes by location or language
High friction targets
- Login-like behavior even without login
- Aggressive challenge ramps under repetition
- Device or session binding patterns
- Strong geo controls and anti-automation layers
Risk level drives three routing parameters:
- Allowed rotation speed: high friction targets punish rapid identity churn. When consumer networks are treated differently, controlled use of Rotating Residential Proxies is often a better test than “rotate faster.”
- Session handling: high friction targets force tighter session boundaries.
- Concurrency budget: the same volume that works on low friction can burn high friction quickly.
A useful operational signal is challenge slope. If the challenge rate rises sharply as concurrency increases, the target is effectively higher risk than it looks.
Identity and session rules for collectors
For aggregation work, identity is not only an IP. It is a bundle of signals:
- IP and ASN profile
- Cookies and session tokens
- Header patterns and request order
- Timing, pacing, and burst shape
- Regional signals such as locale and time zone
Decide early if a workflow needs a stable identity:
Stable identity mode
- Monitoring where continuity matters
- Targets that serve different content across sessions
- Any flow that builds trust over time
Anonymous fetch mode
- Broad discovery where depth is shallow
- Low friction content
- One-off fetches with low repeat frequency
Session rules that prevent most failures:
- Isolate cookies per job: never share cookie jars across targets unless you’re intentionally modeling the same identity.
- Pin session to routing policy: if rotation is “fixed per job,” the session must follow that boundary.
- Retire sessions on key events: repeated challenges, suspicious redirects, or unexpected login gates are session retirement triggers.
- Record session lineage: every response should be attributable to a session id and a route id.
Protocol choice is part of operational reliability. When tooling constraints matter, start from Proxy Protocols, then pick between HTTP Proxies and SOCKS5 Proxies based on your client stack and throughput needs.
If you can’t trace a bad result back to the exact session boundary, debugging becomes guesswork.
IP pool choices and rotation policies
Pick pool types based on what you need to preserve.
Datacenter
- Best for throughput and cost control
- Works well for low friction and many moderate targets
- Requires careful pacing and retries to avoid fast block ramps
For many aggregation jobs, starting with Static Datacenter Proxies keeps identity stable enough to diagnose pacing and retry issues before adding rotation complexity.
Residential
- Useful when targets treat consumer networks differently
- Better for moderate to high friction access patterns
- Needs stricter rotation control to avoid noisy churn
If the workflow needs continuity, Static Residential Proxies are often easier to operate than “rotate until it works.”
ISP
- Useful when you need a stable identity feel with fewer surprises
- Often better for monitoring and long-lived tasks that must look consistent
- Typically requires tighter pool allocation per workflow
Mobile
- Useful when the target expects app-like traffic or tough consumer gating
- Expensive and should be used deliberately, not as a default fallback
Now define rotation modes:
- Fixed per job: one route identity per scheduled run. Good for monitoring and change detection.
- Fixed per target: pin per domain or per endpoint group. Good when a target reacts to cross-path identity mixing.
- Timed rotation: rotate on a clock. Good for discovery jobs where identity continuity is less important.
- Event-driven rotation: rotate on specific error states or challenge ramps. Good when you have strong observability.
Guardrails that keep rotation sane:
- Do not rotate on every retry.
- Do not rotate mid-session for targets that are sensitive to continuity.
- Define a maximum number of distinct identities per unit time per target.
Rotation is a lever. If you pull it too often, you create a signal pattern that looks artificial.
Decision rules that pick a routing plan
A routing plan should be describable as rules, not a vibe.
Start with four inputs:
- Risk tier of the target
- Session need for continuity
- Volume and concurrency goals
- Geo accuracy requirements
Then generate policy choices:
Pool type
Low friction: datacenter first.
Moderate: datacenter with conservative pacing, then residential if needed.
High friction: residential or ISP with strict session boundaries, mobile only when justified.
Rotation
Monitoring: fixed per job or fixed per target.
Discovery: timed rotation with caps.
High friction: event-driven rotation with session retirement, not constant churn.
Concurrency budget
Set per target. Enforce it.
If you can’t enforce it, you don’t have a budget.
Stop rules
Define “pause conditions” for the scheduler:
- Challenge rate crosses a threshold over N minutes
- 403 or 429 burst exceeds a ceiling
- Session loss spikes after policy changes
Fallback ladder
Change the least invasive thing first:
- Reduce burst and smooth pacing
- Reduce concurrency
- Tighten session boundaries
- Adjust rotation triggers
- Switch pool type
If your first reaction is “switch to residential,” you will overspend and still fail on bad session and retry design.
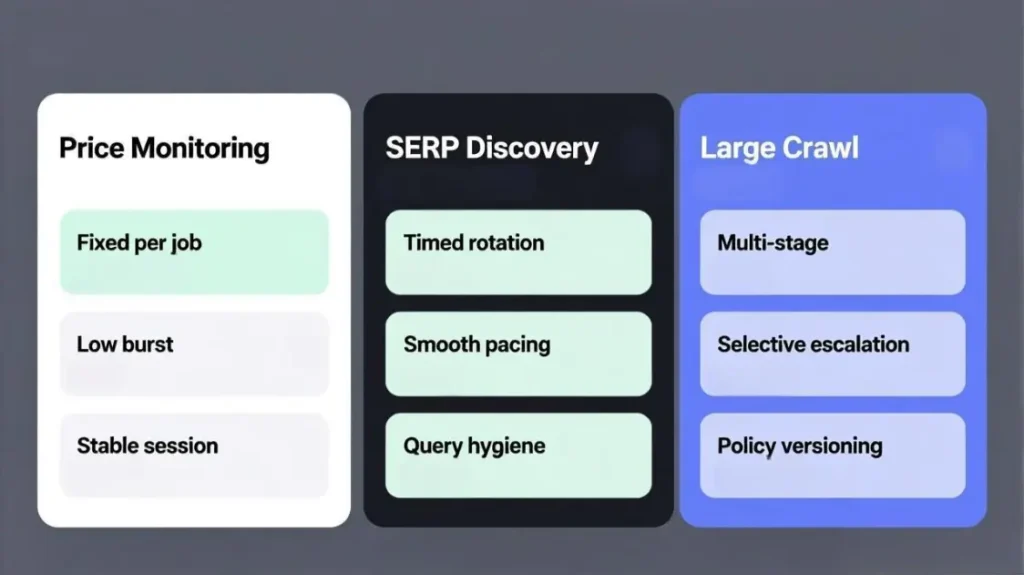
Workflow one Price and inventory monitoring
Monitoring is about stable comparisons over time. Routing must preserve continuity more than raw throughput.
Routing setup
- Prefer fixed per job identity for each target domain.
- Keep concurrency modest and consistent. Avoid bursty checks at the top of each hour.
- Segment pools by target category if risk differs across retailers. For continuity-sensitive runs, this maps cleanly to Static Residential Proxies when consumer-network behavior matters.
Scheduling that reduces pressure
- Stagger polling windows so you don’t create predictable spikes.
- Use incremental checks where possible: monitor only top SKUs frequently, long-tail less often.
- Cache stable assets and avoid re-fetching heavy resources.
Handling common monitoring edge cases
- Geo-locked pricing: bind geo routing to the job, don’t “discover geo” dynamically mid-run.
- Localization shifts: record locale headers and ensure they stay consistent.
- Soft blocks that change content: keep a control route to compare against, so you can detect “poisoned” pages.
If monitoring pages are inconsistent, you may be measuring routing artifacts rather than real market change.
Workflow two SERP and marketplace discovery
Discovery is high repetition with predictable query structures. Targets watch burst patterns and query similarity.
Routing setup
- Use distributed routing that limits repeat pressure on the same identity.
- Keep concurrency conservative and prefer smoother pacing.
- Rotate on a schedule, but cap identities per target per hour to avoid noisy churn. If you need scalable query throughput with controlled rotation, a practical mapping is Rotating Datacenter Proxies plus strict pacing and retry budgets.
Query hygiene
- Deduplicate keywords and normalize queries to reduce redundant hits.
- Randomize query order and insert cool-down intervals.
- Avoid repetitive templated query sequences that scream automation.
Validation and quality control
- Watch for degraded SERP quality: missing modules, strange localization, or repeated captchas.
- Compare a small sample against a control route to detect soft blocks.
- Track rank drift by route id. If ranks shift only on certain routes, routing is influencing what you see.
For discovery, accuracy failures are often silent. Observability is the difference between “we lost coverage” and “we collected garbage.”
Workflow three Large crawl and change detection
Large crawls fail when routing is flat. Different crawl stages need different routing posture.
Multi-stage crawl design
- Seed stage: fast, low-cost routing to map paths and gather URLs.
- Fetch stage: stable routing posture per target group to reduce churn.
- Render or extract stage: only escalate to heavier routing where needed.
Selective escalation
- Don’t render everything. Render only pages that require JS for the data you need.
- Use content parity checks: if the HTML fetch contains required data, avoid heavier steps.
- Escalate pool type only for specific endpoints, not the whole domain.
Replay and debug
- Store response hashes and key headers per route id so you can reproduce issues.
- Keep a record of route policy versions. When a crawl breaks, you need to know what changed.
- Treat routing updates like deployments: staged rollout, metrics check, rollback plan.
Change detection that is sensitive to routing differences will generate false alerts. Reduce routing variability before you trust change signals.
Common mistakes that break aggregation runs
These are the failures that show up repeatedly in real pipelines:
- One pool for every target
Different targets have different risk and continuity needs. A single pool forces bad compromises. - Rotation during continuity flows
Rotating identity mid-session breaks trust patterns and increases challenges. - Retry storms
Retrying without backoff and budgets amplifies blocks and burns pools quickly. - Shared sessions across jobs
Cookie and token leakage ties unrelated workflows together and creates association signals. - No stop rules
Schedulers that keep pushing during challenge spikes turn temporary friction into full bans. - Misreading symptoms
“Proxy quality” is blamed when the real issue is pacing, concurrency, or session boundaries.
Most of these mistakes are policy problems. Fixing them is cheaper than switching providers or buying larger pools.
Operational checklist for routing reliability
Use this as a preflight and runtime guardrail.

Preflight checklist
- Assign risk tier per target group.
- Define session boundaries per workflow.
- Choose pool type per workflow, not globally.
- Set rotation policy with explicit caps.
- Set concurrency budgets per target.
- Define retry budgets and backoff rules.
- Tag requests with route id, session id, and workflow id.
Runtime checklist
- Monitor block and challenge rate per target and per route id.
- Alert on spikes, not just absolute numbers.
- Enforce stop rules at the scheduler level.
- Log “why” for route decisions, not only “what route.”
- Keep a control route for comparison on high value targets.
Post-run checklist
- Compare success rates by target and by routing policy version.
- Identify which layer caused improvement or regression.
- Retire routes that consistently degrade quality.
- Update the risk map and decision rules as targets evolve.
Cost guardrail: if you are paying for “more identities” to compensate for weak pacing, retries, or session boundaries, you will overpay and still get inconsistent results. Fix policy first, then consider higher-capacity pools like Unlimited Residential Proxies only when the workflow truly needs it.
Daniel Harris is a Content Manager and Full-Stack SEO Specialist with 7+ years of hands-on experience across content strategy and technical SEO. He writes about proxy usage in everyday workflows, including SEO checks, ad previews, pricing scans, and multi-account work. He’s drawn to systems that stay consistent over time and writing that stays calm, concrete, and readable. Outside work, Daniel is usually exploring new tools, outlining future pieces, or getting lost in a long book.
FAQ
1. When is datacenter routing good enough for aggregation
Direct answer based on risk tier and what failure looks like for the workflow. Include a rule of thumb and what to measure.
2. How fast should I rotate for monitoring jobs
Explain why fixed per job often beats timed rotation. Give measurable triggers for rotation.
3. Should I pin one identity per target or per run
Compare the two pinning strategies and describe when each reduces challenge slope.
4. What should I change first when challenges spike
Provide the fallback ladder: pacing, concurrency, session policy, rotation triggers, then pool type.
5. How many identities should a small team start with
Give a starting point based on target count and schedule frequency, and emphasize budgeting with caps.
6. Why VPN patterns fail in scraping workflows
Explain that VPNs are not a routing policy system and don’t solve session isolation, rotation control, or observability.
7. How do I detect soft blocks and poisoned content
Explain control routes, parity checks, and route-specific result drift monitoring.
8. What logs matter most for debugging routing
List route id, session id, policy version, error class, backoff decisions, and target tier.