Datacenter Proxies for Real Workloads
Datacenter proxies are the right tool when you need high throughput, predictable latency, and controllable cost per successful request—and you’re willing to operate inside clear risk boundaries. This guide targets practitioners who already know what proxies are, but want a decision framework, measurable validation gates, reproducible labs, and an ops playbook that holds up under production traffic. For a fast baseline on features and modes, see Datacenter Proxies.
Who this guide is for and what you will be able to prove
If you run price monitoring, inventory checks, SERP sampling, public page crawling, or other stateless request workloads, you need two outcomes:
- You can choose a proxy mode that matches your workload constraints.
- You can prove a pool is production-ready using pass fail signals and an evidence bundle.
The operating goal is throughput with controlled risk
Datacenter IPs are attractive because they tend to be:
- Fast and consistent at the network layer
- Easy to scale with predictable concurrency
- Cost-efficient per GB or per request in many scenarios
They also fail in predictable ways:
- Range reputation collapses under velocity
- Anti-bot systems score you on more than IP
- Shared subnets inherit neighbor abuse
The proof standard is gates plus an evidence bundle
Every claim should map to a test and an artifact. Your proof standard should include:
- A gate scorecard with thresholds
- Raw request logs with timestamps and status codes
- Latency percentiles and retry counts
- A sample of egress IPs with ASN and geo
- Notes on rotation semantics and observed failure modes
What datacenter proxies mean in practice
A datacenter proxy is a proxy service whose egress IPs are predominantly associated with hosting providers and non-consumer networks. That single fact changes how targets score you and how quickly a pool can burn under automation patterns.
What makes an IP a datacenter IP operationally
Operationally, “datacenter IP” usually implies:
- The ASN and netblocks look like cloud or hosting ranges
- Ranges can be resold across multiple brands
- Reputation can shift at subnet or ASN scope, not just per IP
For operators, the practical takeaway is simple: you manage pools, subnets, and failure curves, not “one IP.”
Static vs rotating and dedicated vs shared as failure modes
Think in failure modes, not labels:
- Static reuse is stable until velocity triggers blocks, then recovery is slow.
- Rotating is great for stateless fetch, but aggressive churn can look suspicious.
- Dedicated avoids neighbor abuse, but does not guarantee good reputation.
- Shared is cheaper, carries collateral risk, and can swing faster.
Decision framework: when datacenter proxies fit and when they fail
Use this quick picker to avoid expensive misfits.
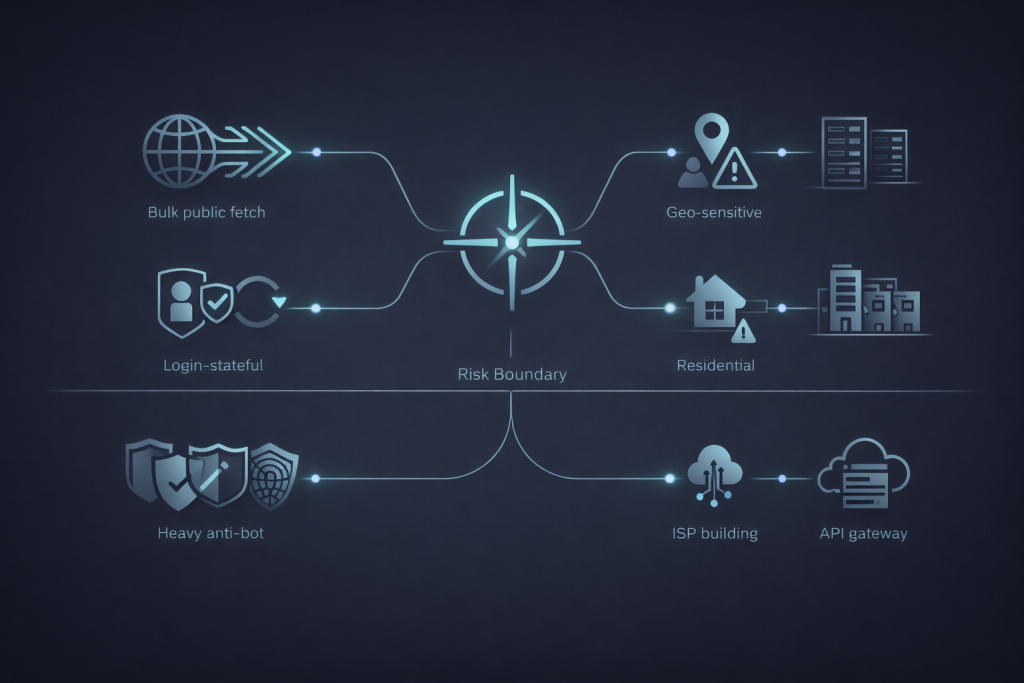
Best fit workloads
Datacenter proxies usually fit when:
- Requests are stateless and do not require long-lived identity
- You can tolerate occasional IP loss and enforce pool hygiene
- You measure success by cost per successful request, not cost per IP
Common long-tail scenarios you should explicitly test for:
- Datacenter proxies for price monitoring at scale with a strict success-rate floor
- High concurrency proxies for catalog crawling with low timeout budgets
- Datacenter proxy pools for SERP sampling with ramp-and-soak stability requirements
High risk workloads where datacenter IPs fail first
Datacenter proxies often fail first for:
- Login, checkout, account creation, session-bound flows
- Strong geo enforcement tied to identity scoring
- Targets with aggressive bot management where IP is only one signal
If your workload includes stateful identity and continuity, datacenter proxies are rarely the safe default.
What to use instead when datacenter proxies fail
Match the alternative to the failure:
- Need higher trust IP reputation: residential or mobile
- Need stable identity with fewer hosting signals: ISP proxies
- Need fewer moving parts for specific endpoints: a scraping API
The cost model that matters is cost per successful request
Use this formula:
- Cost per success = total spend ÷ successful responses
Track it by:
- Target domain
- Proxy pool or subnet slice
- Request type such as HTML pages vs JSON endpoints
- Concurrency tier
When you need frequent rotation for stateless throughput, Rotating Datacenter Proxies is a common operational shape to evaluate.
Threat model and risk boundaries
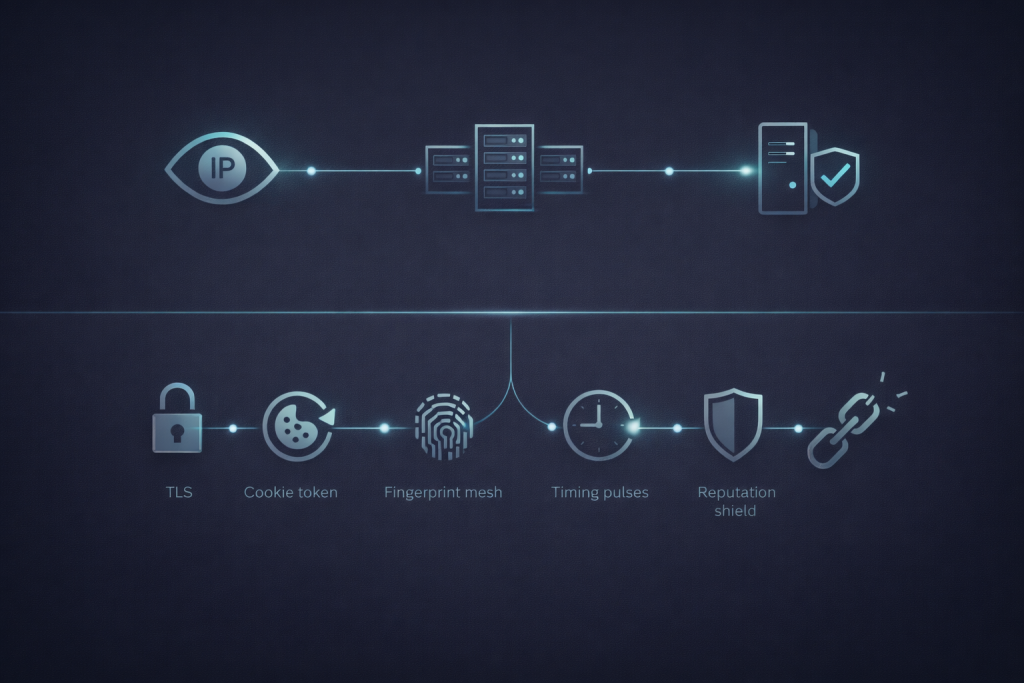
Threat modeling keeps your team honest. Datacenter proxies change routing, they do not create safety.
What datacenter proxies do not guarantee
Datacenter proxies do not guarantee:
- Anonymity against a determined target
- Account safety
- Immunity to bans or blocks
- Compliance with site terms or applicable law
They are routing infrastructure, not an identity cloak.
Detection surfaces you cannot proxy away
Targets routinely score you on signals beyond IP:
- TLS handshake characteristics and client behavior
- Cookies and session artifacts
- Browser fingerprints and automation traces
- Timing patterns and retry rhythms
Reference: TLS 1.3 behavior and negotiation is defined in RFC 8446: The Transport Layer Security TLS Protocol Version 1.3.
Abuse and collateral risk on shared subnets
When many customers share a range, reputation can shift as a group:
- A few abusive tenants can poison a subnet
- A target can block an ASN-wide slice
- Your success rate can drop across multiple domains in the same time window
Compliance and operational boundaries
If your workload resembles automated threat patterns, expect tighter defenses. OWASP’s Automated Threats project is a useful framing for how defenders think about bots at scale: Automated Threats to Web Applications.
Verification playbook with measurable pass fail signals
Validate with gates, not vibes.
Gate 1: Egress identity is what you think it is
Prove:
- Egress IP matches the pool you requested
- ASN and geo match your selection constraints
- You are not accidentally chaining proxies
Pass signals:
- Stable egress within expected ranges
- No unexpected proxy headers added upstream
Fail signals:
- Geo mismatch at random intervals
- Egress flips when you expect stickiness
Gate 2: Routing and DNS behavior match your intent
Prove:
- HTTP egress is remote
- DNS resolution behavior matches your intended model
Fail signals:
- “Remote IP” looks correct, but DNS resolves locally, producing inconsistent geo, caching, or leakage side effects.
Gate 3: Target acceptance holds under ramp and soak
Prove stability under increasing load and then steady load.
Measure:
- Success rate
- 403 and 429 rates
- Timeout rate
- p95 latency and tail growth
- Retry amplification
Many defenses express pressure as 429 when you exceed acceptance thresholds. Cloudflare’s public documentation is a good reference point for rate limit behavior patterns: Cloudflare API rate limits.
Gate 4: Stability holds under reuse and concurrency
Prove:
- Reuse does not decay sharply over time
- Concurrency does not cause a nonlinear collapse
- Pool is not concentrated in a single weak subnet
Gate 5: Operability and observability are production-grade
Prove:
- You can attribute failures to subnets, targets, and policies
- Replacement and cooldown are supported
- Protocol behavior matches your client stack needs
If you need to reason about protocol-level behavior and routing semantics, Proxy Protocols is a useful reference.
Lab 1: Fast identity and leak checks with CLI
Goal: decide in 10 minutes whether a pool is worth deeper testing.
Confirm egress IP, ASN, and geo from multiple vantage points
Run 3–5 requests and record results:
# Egress IP
curl -s https://api.ipify.org; echo
curl -s https://ifconfig.me; echo
# Headers as seen by a neutral reflector
curl -s https://httpbin.org/headers | head
What to look for:
- Egress stability when you expect stickiness
- Unexpected forwarding headers that indicate chain or transparency
- Inconsistent identity between reflectors that correlates with failures
Confirm DNS behavior
If your stack supports remote DNS through the proxy, compare outcomes. At minimum, capture a baseline:
dig +short example.com @1.1.1.1
Evidence to store:
- Resolver used
- Answer variance across runs
- Correlation between DNS behavior and geo anomalies
Lab 2: Ramp and soak stability test with a small script
Goal: quantify block curves, burn risk, and tail latency under real concurrency.
Minimal Python ramp and soak skeleton
import time, json, statistics
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
URL = "https://example.com/"
TIMEOUT = 20
def one():
t0 = time.time()
try:
r = requests.get(URL, timeout=TIMEOUT)
return {"ok": r.status_code < 400, "code": r.status_code, "ms": (time.time()-t0)*1000}
except Exception:
return {"ok": False, "code": "timeout_or_error", "ms": (time.time()-t0)*1000}
def run(concurrency, seconds):
out = []
end = time.time() + seconds
with ThreadPoolExecutor(max_workers=concurrency) as ex:
while time.time() < end:
futs = [ex.submit(one) for _ in range(concurrency)]
for f in as_completed(futs):
out.append(f.result())
return out
def summarize(rows):
ms = [r["ms"] for r in rows]
codes = {}
for r in rows:
codes[str(r["code"])] = codes.get(str(r["code"]), 0) + 1
ms_sorted = sorted(ms)
p95 = ms_sorted[int(0.95*len(ms_sorted))-1] if ms_sorted else None
return {"n": len(rows), "p50_ms": statistics.median(ms) if ms else None, "p95_ms": p95, "codes": codes}
plan = [(5, 120), (20, 120), (50, 900)] # ramp then soak
results = []
for c, s in plan:
rows = run(c, s)
results.append({"concurrency": c, "seconds": s, "summary": summarize(rows)})
time.sleep(10)
print(json.dumps({"ts": time.time(), "results": results}, indent=2))
Pass signals:
- Success rate stays above your floor as concurrency increases
- 429 and 403 remain bounded and do not trend upward during soak
- p95 grows modestly rather than exploding
Fail signals:
- Blocks climb during soak even when traffic stays flat
- Tail latency balloons while median stays stable
- Retries raise block rates instead of recovering success
Troubleshooting flow for operators
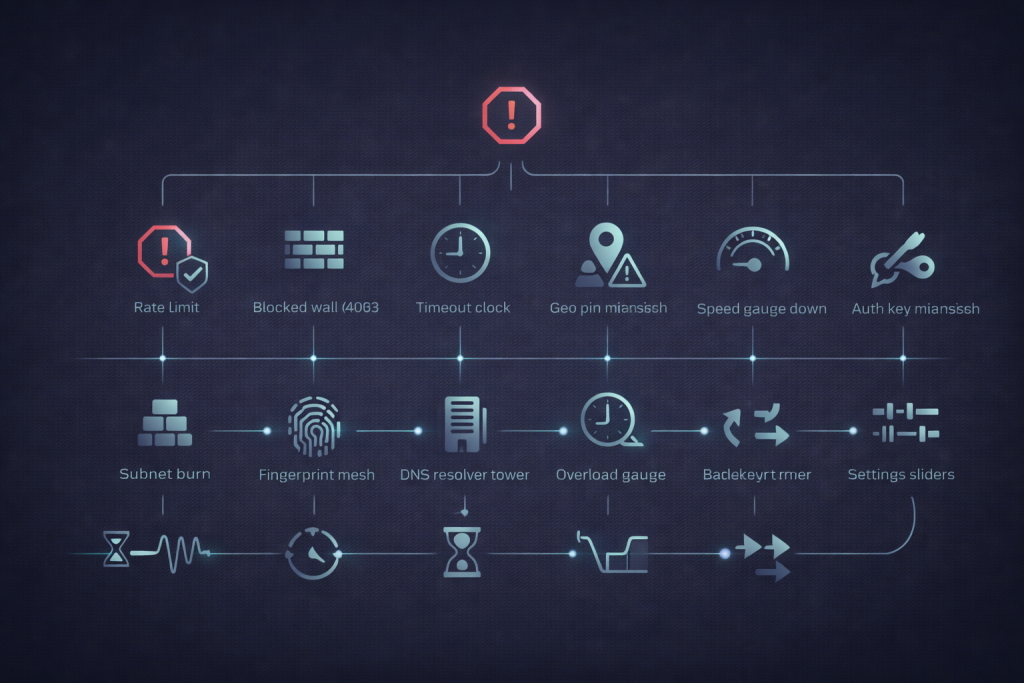
| Symptom | Likely cause | First fix |
|---|---|---|
| Sudden 429 spike | Rate ceiling hit | Cut concurrency, add exponential backoff with jitter |
| 403 climbs during soak | Subnet reputation burn | Quarantine subnet, rotate to a separate range |
| Captcha appears after a few requests | Scoring beyond IP | Reduce churn, adjust client timing and state handling |
| Timeouts grow and p95 explodes | Overloaded upstream or congestion | Shard pool, lower concurrency, verify node capacity |
| Geo mismatches intermittently | Pool mixing or DNS path mismatch | Pin pool to region, validate DNS model again |
| Success varies wildly by target | Target-specific defenses | Separate pools by target class and tighten pacing per target |
Procurement checklist: what to ask a provider
These questions surface constraints before integration.
IP supply and provenance
- Which ASNs do you source from and how often do ranges change
- Do customers overlap on the same upstream blocks across brands
- How do you handle subnet-wide abuse events and replacements
Rotation semantics
- Rotate per request, per time window, or on demand
- Sticky options and maximum reuse recommendations
- Pool size per geo and per ASN slice
Concurrency and protocol support
- Connection limits and any per-IP throttles
- HTTP and SOCKS5 availability, auth methods, and port ranges
- Whether any traffic is intercepted or modified in transit
SOCKS5 behavior is defined in RFC 1928, which is useful when debugging protocol-level routing and authentication issues: SOCKS Protocol Version 5.
For deterministic stickiness in stable-affinity workloads, Static Datacenter Proxies is the mode most operators evaluate.
Ops checklist: monitoring, rotation, retries, safety rails
What to monitor continuously
- Success rate and block rate by target
- 403, 429, timeout rates
- p50 and p95 latency
- Retry count distribution
- Unique IP count and subnet concentration
- Error budget burn per target
Rotation strategy selection by workload
- Public stateless fetch: rotate per request or short sticky window
- Pagination and continuity: sticky window with limited reuse
- Identity-sensitive flows: avoid datacenter proxies unless gates stay clean under soak
Retry policy that does not amplify blocking
- Exponential backoff with jitter
- Low max retries
- Stop conditions when 403 or 429 rises above a threshold
Pool hygiene
- Quarantine hot subnets
- Cooldown timers after block bursts
- Shard pools by target class to prevent cross-contamination
MaskProxy users commonly implement subnet sharding and cooldown rails first, because it reduces range-wide burn without over-rotating.
Common misconceptions to ignore in marketing pages
- “Anonymous proxies” means “your IP changes,” not “your identity disappears.”
- “Dedicated IP equals unblocked” is false when the subnet is burned.
- “Rotation fixes everything” is false when churn itself becomes a scoring signal.
- “Faster proxies are better” is false if acceptance collapses under load.
EEAT block: author stance, methodology, evidence
Author stance
- Evidence-first operator mindset
- Optimize for repeatable stability, not screenshots of a single success
Test methodology
- Validate with gates: identity, DNS model, ramp and soak, reuse stability, operability
- Record metrics by target, subnet, concurrency tier, and time window
Evidence bundle checklist
- Request logs with timestamps and status codes
- Latency percentiles and timeout counts
- Retry counts and backoff settings
- Egress IP samples with ASN and geo
- Notes on rotation mode and pool composition
- A saved JSON summary from the ramp and soak run
Conclusion
Datacenter proxies win when you treat them like production infrastructure: choose the right workload lane, validate with gates, store evidence, and operate with pool hygiene. When your client stack benefits from SOCKS routing rather than HTTP proxy semantics, SOCKS5 Proxies is a practical option to keep available.
Daniel Harris is a Content Manager and Full-Stack SEO Specialist with 7+ years of hands-on experience across content strategy and technical SEO. He writes about proxy usage in everyday workflows, including SEO checks, ad previews, pricing scans, and multi-account work. He’s drawn to systems that stay consistent over time and writing that stays calm, concrete, and readable. Outside work, Daniel is usually exploring new tools, outlining future pieces, or getting lost in a long book.
FAQ
1.When do datacenter proxies fit best
Stateless, high-throughput workloads like public crawling, price monitoring, and SERP sampling where you can rotate and pace.
2.When do datacenter proxies fail fast
Login, checkout, long sessions, and heavy anti-bot targets where IP is only one of many signals.
3.How do I validate a pool quickly
Run Gate 1 and Gate 2 first: verify egress identity, then verify DNS and routing behavior.
4.Why do I get 429 or 403 spikes
You are hitting acceptance thresholds or range reputation limits. Reduce concurrency, add backoff with jitter, and shard subnets.
5.What metrics matter most
Success rate, block rate, timeout rate, and p95 latency—tracked per target and subnet.
6.How do I size the IP pool
Size by cost per successful request and reuse tolerance. If blocks rise during soak, you need more range diversity or lower velocity.
7.How do I recover from a ban wave
Stop ramp, snapshot evidence, quarantine the subnet slice, and shift traffic to a clean range with stricter pacing.
8.Should I use rotating or static
Rotating for stateless throughput. Static for stable affinity when targets tolerate reuse.