Proxy Protocols vs PROXY protocol in production and how to preserve client IP correctly

Search demand around “Proxy Protocols” is broader than the real deployment question most operators need to answer. Some readers are comparing HTTP proxy behavior, CONNECT tunneling, SOCKS5, and reverse proxy identity forwarding. Others are specifically trying to decide whether PROXY protocol is the right way to preserve client IP across a load balancer, reverse proxy, or ingress chain. That distinction matters because client identity directly affects logging, rate limiting, access control, geo policy, abuse handling, and audit quality. A broad reference such as Proxy Protocols can help frame the category, but production design still depends on which layer carries identity and which hop is allowed to define it.
The common failure is not lack of syntax knowledge. The common failure is combining mechanisms that operate at different layers and then trusting the wrong signal. Many teams inherit an architecture where one proxy forwards TCP, another appends HTTP headers, and the backend consumes whichever client field appears first. That creates inconsistent logs, weak IP-based controls, and confusing incidents when health checks, TLS expectations, or multi-hop forwarding paths change. The real question is not simply what PROXY protocol is. The real question is which client IP preservation method is correct for this traffic type, this trust boundary, and this operational model.
Why the difference between proxy protocols and PROXY protocol matters
The phrase proxy protocols is often used loosely as a category term. In practice it may refer to HTTP proxy behavior, the CONNECT method, SOCKS5 negotiation, upstream proxy chaining, and metadata-forwarding approaches used by reverse proxies. PROXY protocol, by contrast, is a specific connection preamble originally associated with HAProxy that carries source and destination connection information before the application payload begins. HAProxy’s documentation makes the sender and receiver contract explicit through accept-proxy, send-proxy, and send-proxy-v2, and that contract is the first production boundary operators need to get right. HAProxy client IP preservation guide
That distinction becomes operationally important when teams compare X-Forwarded-For with PROXY protocol and assume the two are interchangeable. They are not. X-Forwarded-For is an HTTP-layer mechanism. PROXY protocol is connection metadata that appears before application data. Native client IP preservation is different again because it avoids an added metadata layer and instead depends on network path and platform capabilities. AWS documents client IP preservation and proxy protocol as separate target-group attributes for Network Load Balancers, which is exactly why they should be treated as separate design choices rather than variants of the same feature. AWS Network Load Balancer target group attributes
This is also where long-tail search intent splits into more practical questions. Some operators search for proxy protocol vs x-forwarded-for. Others search for proxy protocol v1 vs v2, client IP preservation behind TLS termination, or how to preserve real client IP through a reverse proxy and load balancer chain. A strong production article has to satisfy all of those search paths while still keeping the core idea clear. When teams compare layered traffic behavior across shared infrastructure, references such as Residential Proxies can help clarify proxy categories and deployment context, but the narrower identity-preservation problem still has to be solved at the correct protocol boundary.
How to choose the right client IP preservation method
There are four common approaches, and each solves a different class of problem.

The first is HTTP header forwarding, usually X-Forwarded-For or Forwarded. This is often the simplest answer for pure HTTP services because reverse proxies, ingress controllers, CDNs, and applications already understand it. NGINX documents real_ip_header, set_real_ip_from, and recursive trust behavior for this model. The operational benefit is simplicity. The operational risk is trust. Header-based client identity is only safe when the proxy that inserts or appends the header is trusted and alternate paths are blocked or normalized. NGINX real IP module documentation
The second is PROXY protocol, which is usually the better fit for non-HTTP TCP services, mixed proxy stacks, or edge-to-backend paths where identity must be conveyed before the application protocol is parsed. This includes database access paths, mail systems, custom TCP services, and L4 load balancer topologies where HTTP headers are unavailable or not authoritative. It is also useful when the receiver needs a transport-level signal for the original client address rather than a header interpreted later by application logic.
The third is native client IP preservation. This is attractive because the backend sees the original source address directly without requiring an extra parsing step. When the platform supports it and the topology satisfies the right conditions, this can be the cleanest solution. It reduces the chance of downstream disagreement over which identity field is authoritative and can simplify operational reasoning.
The fourth is transparent or original-source approaches. These can preserve source fidelity without adding a separate metadata layer, but they are more demanding operationally because they depend on routing behavior, socket semantics, platform constraints, or advanced proxy features. Envoy’s IP transparency documentation is useful here because it shows that several techniques exist, but they differ significantly in complexity, applicability, and trade-offs. Envoy IP transparency overview
A practical rule works well in production. Use headers when the path is purely HTTP and the trust model is clean. Use PROXY protocol when the path is TCP-oriented, metadata must arrive before application parsing, and both ends are under your control. Use native client IP preservation when the platform supports it cleanly. Use transparent methods only when you specifically need that network behavior and can support the extra operational complexity. In broader egress design, the distinction between HTTP Proxies and transport-oriented proxy behavior can help frame protocol selection, but client identity design still has to be handled deliberately at ingress and backend boundaries.
How PROXY protocol behaves across versions, TLS boundaries, and multi-hop chains
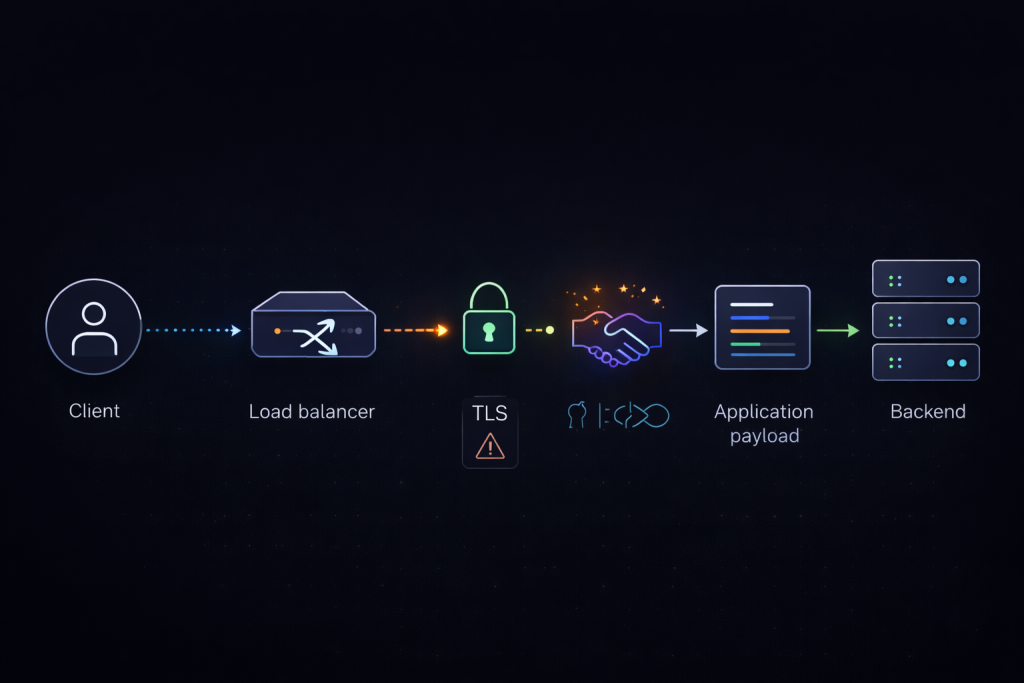
Version choice is not only a matter of syntax. PROXY protocol v1 is text-based and easier to inspect manually during debugging. PROXY protocol v2 is binary, more compact, and extensible through TLVs. In many modern deployments, v2 is the better default when both ends support it because it is more structured and aligns well with managed infrastructure implementations. v1 remains useful where visibility and debugging convenience matter more than feature depth.
The multi-hop case is harder still. A single trusted sender is usually straightforward. A chain containing edge load balancers, internal reverse proxies, service-mesh sidecars, TCP gateways, or mixed proxy layers is not. AWS documents that more than one PROXY header can appear in a traffic path under certain conditions. That means the real production problem is no longer just whether PROXY protocol is enabled. The real problem is which hop is authoritative and which metadata should be trusted. If a backend or intermediate proxy trusts the wrong source, the result is worse than losing client IP entirely because logs and enforcement may still appear valid while actually reflecting the wrong client.
This is why the trust boundary must be explicit. Decide where client identity becomes authoritative. Decide which peers are allowed to assert replacement identity. Decide whether downstream controls consume socket source, PROXY metadata, or HTTP headers. Then make logging, ACLs, and rate limits consume that same normalized identity everywhere. Teams running mixed ingress and egress paths through MaskProxy still face the same requirement: identity must be normalized once, trusted intentionally, and reused consistently across the stack.
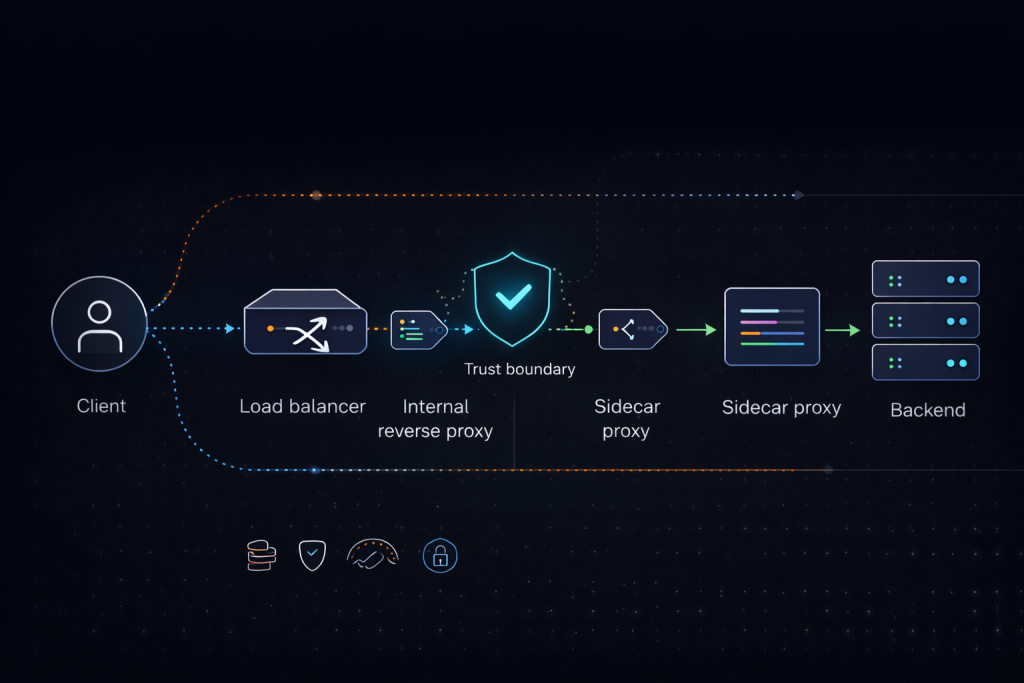
What breaks first when PROXY protocol is enabled incorrectly
The most common failure is enabling PROXY protocol on the sender while the receiver still expects raw application data. For HTTP services, the first bytes no longer resemble an HTTP request line. For TLS services, the handshake no longer begins where the receiver expects it. The visible symptom may look like a generic handshake failure, a bad request, or an opaque protocol parse error, but the root cause is usually a mismatch between sender behavior and listener expectation.

The second common failure is trusting identity from the wrong source. Header-based identity without a strict trust list is unsafe, and the same principle applies to PROXY protocol. If the receiving system accepts replacement identity from peers that are not explicitly trusted, the deployment has not solved the client IP problem. It has only moved the spoofing surface deeper into the stack. This is especially dangerous when alternate traffic paths bypass the intended edge hop.
The fourth common failure is inconsistent identity consumption across layers. The load balancer may log one address, the reverse proxy may derive another, and the application may rate limit on a third field. That creates weak abuse analysis, unreliable allowlists, and poor incident traceability. In high-churn infrastructure, those mismatches are often harder to diagnose because network behavior and backend expectations drift over time. That is one reason teams often need a clearer mental model when they work across multiple proxy classes such as SOCKS5 Proxies and reverse-proxy identity paths in the same environment.
How to validate a PROXY protocol deployment before rollout
Start with the listener contract. Confirm which hop sends PROXY protocol and which hop accepts it. Do not rely on inherited assumptions or naming conventions in configuration files. The sender, receiver, and any intermediate TCP-aware device must agree on the exact connection boundary where the metadata appears.
Then inspect the first bytes on the wire. This is one of the fastest ways to confirm whether the receiver is actually seeing a PROXY preamble, whether the version matches expectation, and whether TLS or application data begins in the right order afterward. Packet capture on a controlled validation path is often more useful than application logs alone because it separates identity errors from parsing errors and makes protocol-boundary mistakes obvious.

Next verify the normalized client identity in logs and policy. Access logs, reverse proxy logs, and application-level logs should agree on the same authoritative client field. If rate limiting, allowlists, fraud checks, or audit pipelines still key off the transport peer rather than the normalized client identity, the deployment is incomplete even if the protocol itself is working.
Finally test health checks separately from user traffic. Use the exact listener, target-group, and forwarding behavior that production will use. The health-check path must either understand the added metadata or bypass the path where PROXY protocol is expected. Treat this as a chain-validation exercise rather than a single configuration flag. That mindset is usually more reliable in real-world environments. In broader production design, MaskProxy can naturally sit inside the surrounding proxy ecosystem, but identity preservation still succeeds or fails based on trust scope, parsing order, and validation discipline.
Why the best production answer is usually a trust model rather than a protocol preference
There is no universal winner between X-Forwarded-For, PROXY protocol, native client IP preservation, and transparent proxying. The right answer depends on transport layer, trust boundary, number of hops, and operational controls around observability and enforcement.
If the environment is pure HTTP and already standardized around trusted edge proxies, header-based forwarding may be enough. If the traffic path includes non-HTTP TCP services, mixed proxy layers, or a load balancer that must pass identity before the application protocol starts, PROXY protocol is usually the better fit. If the platform can preserve source IP natively and the topology satisfies the platform constraints, that may be simpler. If the requirement is deeper network fidelity, transparent methods may be justified, but only with the routing and operational maturity to support them.
The strongest production design is the one that answers three questions clearly. Which field represents the authoritative client identity. Which systems are allowed to assert or rewrite it. Which logs, controls, and dashboards consume it. Teams that answer those questions early usually avoid the worst client-IP preservation failures. Teams that skip them usually spend more time debugging symptoms than understanding the boundary that caused them.
Daniel Harris is a Content Manager and Full-Stack SEO Specialist with 7+ years of hands-on experience across content strategy and technical SEO. He writes about proxy usage in everyday workflows, including SEO checks, ad previews, pricing scans, and multi-account work. He’s drawn to systems that stay consistent over time and writing that stays calm, concrete, and readable. Outside work, Daniel is usually exploring new tools, outlining future pieces, or getting lost in a long book.
FAQ
1.What is the difference between proxy protocols and PROXY protocol
“Proxy protocols” is a broad category phrase people use for proxy-related transport and forwarding methods. “PROXY protocol” is a specific connection preamble used to pass client and destination metadata before application data.
2.Is PROXY protocol the same as X-Forwarded-For
No. X-Forwarded-For is an HTTP header. PROXY protocol is a transport-level preamble that arrives before application payload on the connection.
3.When should I use PROXY protocol
Use PROXY protocol when you need client identity for TCP services, non-HTTP traffic, or controlled reverse proxy and load balancer chains where both ends support it.
4.Is PROXY protocol v2 better than v1
In many production environments, yes. v2 is binary and extensible, while v1 is text-based and easier to inspect manually.
5.Why do deployments fail after enabling PROXY protocol
The most common causes are protocol mismatch on the receiving side, incorrect trust boundaries, TLS expectation errors, and health-check paths that do not parse the PROXY header correctly.